On-Device Retrieval Augmented Generation Using Agents
Table of Contents
- Introduction
- Motivation
- About
- Demo
- Architecture
- Built With
- Development Journey
- Acknowledgments
Introduction
The full details of this project can be found at the GitHub repository: https://github.com/jianyangg/local-llm.
![]()
On-Premises Multi-Tenancy Agentic RAG
your conversational assistant, powered by your documents
Motivation
-
Uploading highly sensitive documents to the cloud carries inherent cybersecurity risks. Storing these data on-premises and utilising Large Language Models to synthesise knowledge from them can streamline workflows while mitigating security concerns associated with sensitive documents.
-
Existing open-source RAG applications often lack multi-tenant support and rely on traditional document storage methods like vector databases, potentially limiting their performance. This project aims to address these limitations by developing a solution tailored for multi-tenant environments and exploring alternative approaches to document storage for improved performance.
About
- A proof of concept for improved RAG performance with
- Topic Modelling
- Agentic Workflow
- Scalable and easily hosted on any sufficiently powerful computer
- Simple platform to edit and build upon
Demo
Architecture
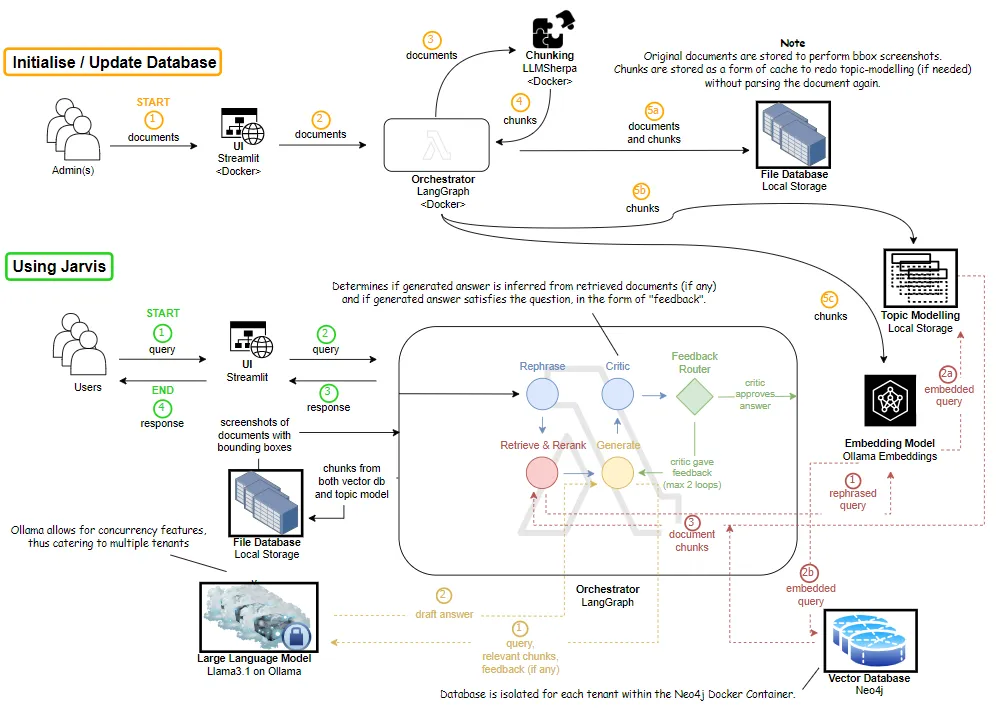
- This architecture is designed to achieve multi-tenancy on-premises, using isolated databases in
Neo4jand concurrent instances ofOllamarunning Meta’sLlama 3.1. - Note: The duplicated file database and orchestrators are for demonstration purposes only. In a production environment, the orchestrator and file database would be a single instance each.
Built With
Development Journey
1. Literature Review (Weeks 1-2)
The initial two weeks focused on understanding Large Language Models (LLMs), RAG, and data retrieval mechanisms. Key concepts studied included vector databases and Retrieval Augmented Generation. Resources explored included LangGraph, Ollama, Meta’s Llama 3.1, Neo4j, and Docker. This foundational research built essential knowledge for the practical work in subsequent weeks.
2. Standard Retrieval Augmented Generation (Weeks 3-5)
During these weeks, I created a basic proof-of-concept for a multi-tenant Retrieval Augmented Generation (RAG) application that could run locally, supporting multiple tenants concurrently. Here’s a detailed breakdown of each aspect worked on:
2.1 Concurrent Llamas
To support multi-tenancy, I ran multiple instances of a Large Language Model (LLM) on-premises. I evaluated options like HuggingFace’s Text Generation Inference and vLLM, ultimately choosing Ollama for its simplicity and ease of managing multiple LLM instances. Ollama’s concurrent inference feature aligned with multi-tenancy requirements, as it determines system capacity before initiating new LLM instances. Meta’s Llama 3.1 model (8 billion parameters) was selected, balancing performance with resource efficiency.
2.2 Chunking Documents
Document chunking was explored to improve document retrieval efficiency. Initially, fixed-length chunking was tested but proved inefficient, as chunks often contained unrelated topics, confusing the retriever. After experimenting, LLMSherpa was chosen for its superior OCR capabilities in parsing documents. LLMSherpa identifies text and tables within a PDF, organizing content hierarchically by recognizing section headers, thus preserving essential context.
2.3 Database Isolation
Tenant-specific data access required isolated vector indexes within a single database. Neo4j was selected for its knowledge graph and vector database capabilities, but due to the limitations of its community edition, I implemented a unique tenant identification system based on hashed credentials to secure tenant data.
3. Refactoring and Containerization (Week 6)
Enhanced the Streamlit UI for front-end document uploads and containerized the application using Docker Compose for one-click deployment.
4. Agents and Topics (Weeks 7-10)
4.1 Topic Modeling
Implemented BERTopic for topic extraction, enabling topic-based retrieval alongside vector database search.
4.2 Bounding Boxes
Integrated bounding boxes to allow users to verify answers against original document sources.
4.3 Agentic Workflow
Developed an actor-critic feedback loop, using a rephraser agent and critic agent to improve the quality of generated answers. The exact architecture is given in the architecture diagram above.
5. Presentation and Reports (Weeks 11-12)
Finalized documentation, created presentation slides, and made the project repository accessible on GitHub: https://github.com/jianyangg/local-llm
6. Limitations and Future Improvements
6.1 Speed
The actor-critic workflow, though accurate, slows down execution. Exploring hardware acceleration options could improve performance.
6.2 Chunking
Current OCR-based chunking could be enhanced with ensemble or semantic methods for better retrieval and answer generation.
6.3 Document Chunk Limit
Investigating flexible document chunk limits may prevent the exclusion of relevant information in large documents.
6.4 Objective Evaluation
More objective evaluation metrics like Ragas could refine performance assessment.
6.5 Knowledge Graph
Further research is needed to improve Cypher command generation for a more accurate knowledge graph structure.
7. Conclusion
The project demonstrates a viable multi-tenant RAG prototype with an actor-critic framework and topic modeling, enhancing RAG performance. Future improvements will focus on refining parsing and chunking methods for improved results.
8. References
- Defence Science and Technology Agency (DSTA). (2024). About Us. DSTA
- Ollama. (2024). FAQ. GitHub
- Meta. (2024). Introducing Llama 3.1. Meta
- Lewis et al. (2020). Retrieval-Augmented Generation for NLP. arXiv
- Hugging Face. (2022). Text Generation Inference. HuggingFace
- Kwon et al. (2023). Efficient Memory Management for LLM Serving. arXiv
- LangGraph. LangGraph
- Sukla, A. (2024). Efficient RAG with Document Layout. Substack
- Wu, J. (2023). Mastering PDFs. Medium
- Neo4j Documentation. Neo4j
- Grootendorst, M. (2022). BERTopic: Neural Topic Modeling. arXiv
- Damodaran, P. FlashRank. GitHub
- Jeong et al. (2024). Adaptive-RAG. arXiv
- Asai et al. (2023). Self-RAG. arXiv
- Yan et al. (2024). Corrective Retrieval Augmented Generation. arXiv
- LLMSherpa Documentation. GitHub
- Es et al. (2023). RAGAS Evaluation. arXiv
Acknowledgments
I am deeply grateful for the opportunity to work at Defence Science & Technology Agency (Enterprise Digital Services). A special mention goes to my internship mentors Yong Han Ching and Benjamin Lau Chueng Kiat for their unwavering guidance, support, and encouragement throughout my internship. Your expertise and insights have been instrumental in this journey, and I am truly appreciative of the time and effort you invested in my development.
I am also thankful to the entire team at Enterprise Digital Services for fostering a welcoming and collaborative environment. It was truly enjoyable working there.